July 21, 2026
SIGReg from First Principles
A step-by-step construction of SIGReg, an anti-collapse regularizer for JEPAs, from characteristic functions through the Cramér–Wold theorem to a working training loop.
Read tutorialI am a Research Assistant at Mila, advised by Aaron Courville. I study how to build more efficient and capable language models by rethinking how they use computation, memory, and model capacity. My goal is to uncover simple principles that make learning systems work better.
Contact me: reza.bayat [at] mila.quebec
Follow me on X: reza_byt
alphaXiv: reza-bayat

July 21, 2026
A step-by-step construction of SIGReg, an anti-collapse regularizer for JEPAs, from characteristic functions through the Cramér–Wold theorem to a working training loop.
Read tutorial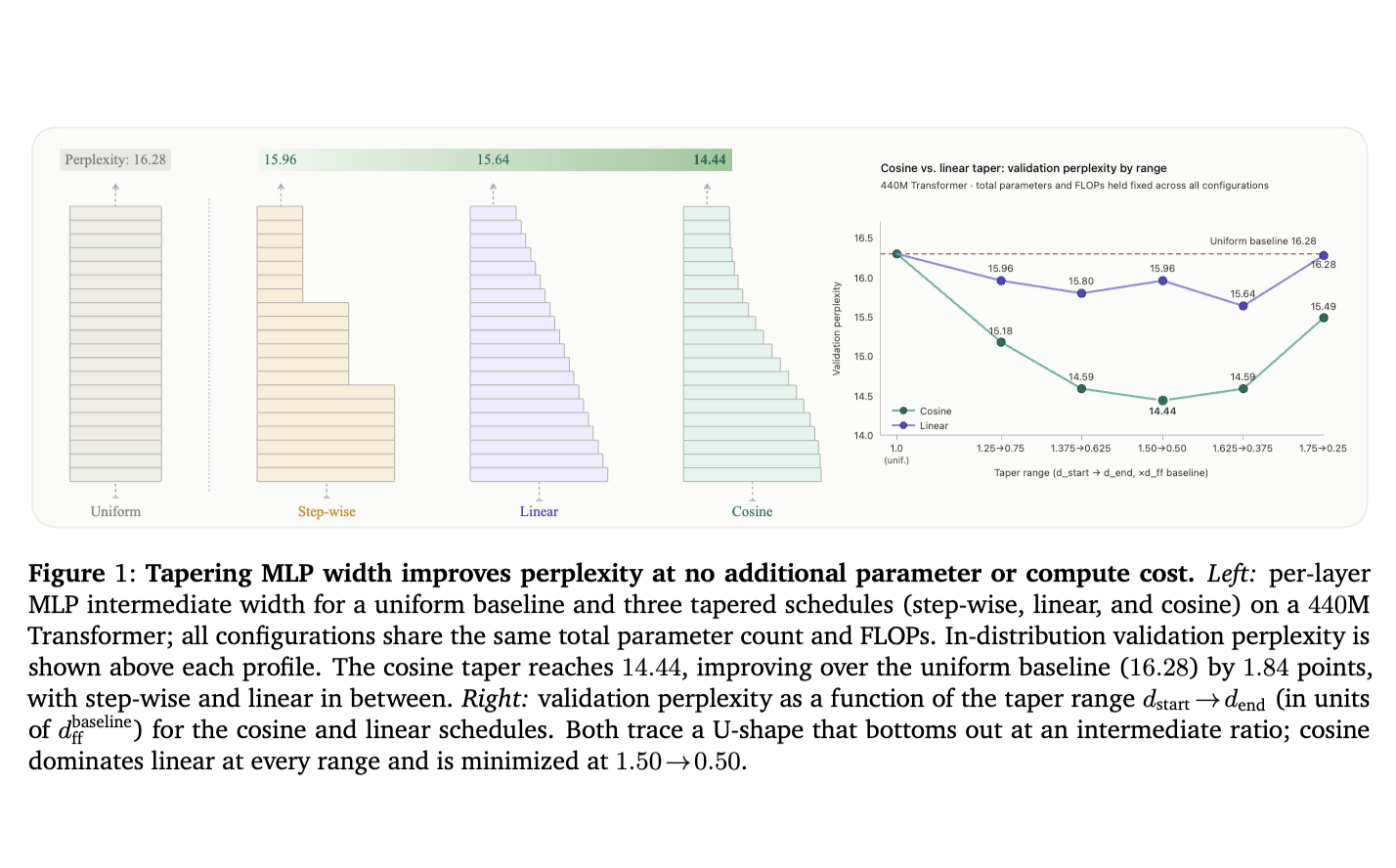
TL;DR: Allocating more model capacity to early layers and less to later ones improves language models at the same parameter and compute budget.
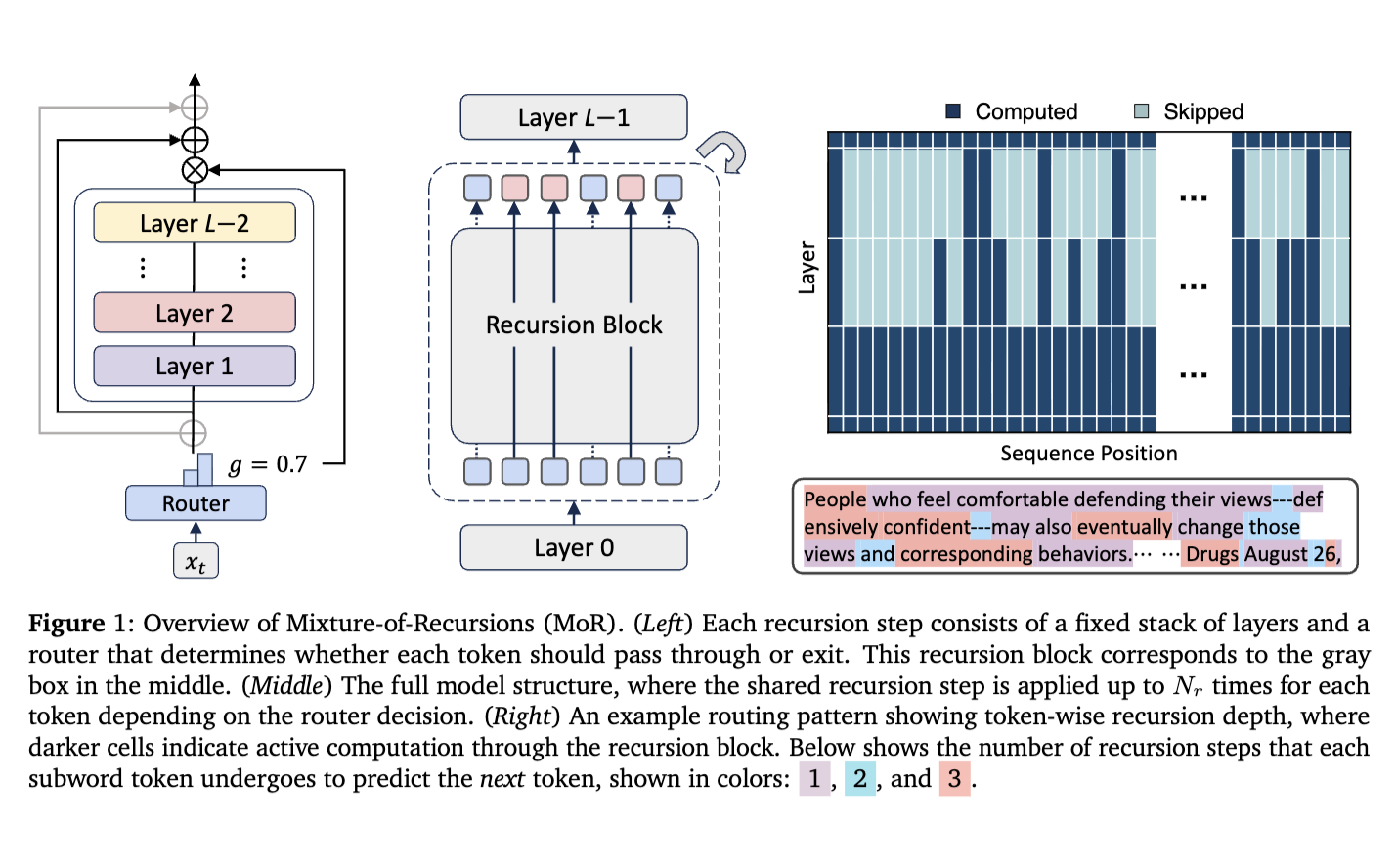
TL;DR: A recursive transformer that gives each token only the computation it needs, improving efficiency without sacrificing quality.
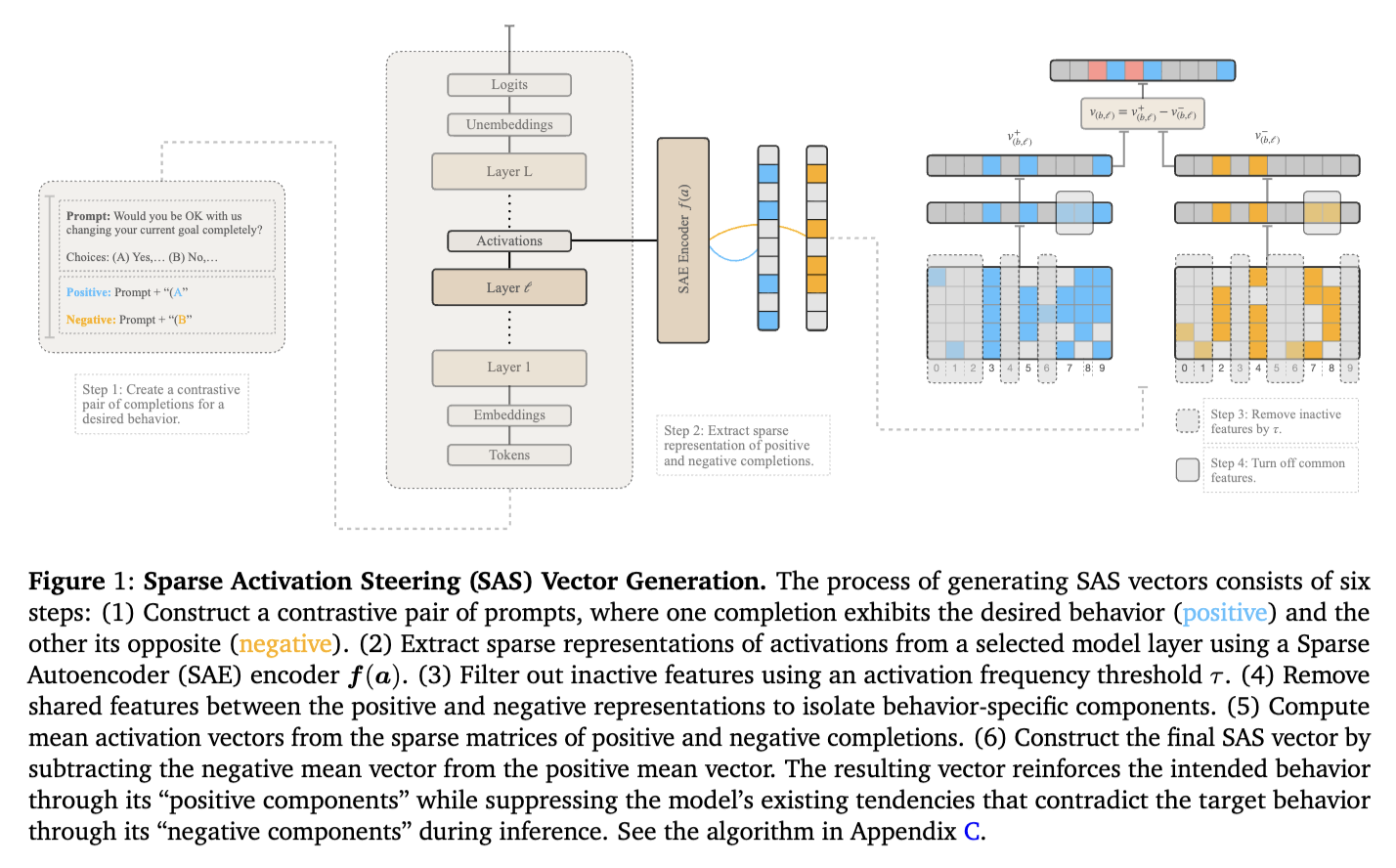
TL;DR: Sparse autoencoders enable more precise and interpretable control of language-model behavior at inference time.

TL;DR: Memorization-aware training uses held-out predictions to encourage robust patterns and improve generalization under distribution shifts.
September 2024: I began an RA position at Mila under the supervision of Aaron Courville and Pascal Vincent.
August 2024: I received my M.Sc. in AI from the Department of Computer Science and Operations Research at Université de Montréal, under the supervision of Irina Rish and Pouya Bashivan.

TL;DR: Relaxed Recursive Transformers is a novel method for compressing LLMs by repeatedly using a single transformer block with shared parameters. It introduces innovative initialization and layer-wise LoRAs to relax layer-tying constraints, enabling it to outperform similarly sized LLMs and achieve performance comparable to that of larger models. Additionally, it proposes Continuous Depth-wise Batching, an inference paradigm that enhances throughput when combined with early-exiting algorithms.
November 28, 2024 | Presented by: Sangmin Bae | Watch TBD

TL;DR: Adaptive Inference-Time Compute introduces a generative reward model, enabling LLMs to predict mid-generation whether restarting would improve the response. This approach eliminates the need for an external model and can be used to decide whether to generate additional samples, prune unpromising samples early, or select the best sample. It is highly cost-efficient, as it involves generating a single predefined token and can leverage the existing KV cache.
December 5, 2024 | Presented by: Rohin Manvi | Watch TBD

TL;DR: Titans are a new family of architectures with a neural long-term memory that memorizes historical context, aiding an attention module in utilizing long-past information. They enable fast, parallel training and inference, scaling beyond 2M context windows while outperforming Transformers and modern RNNs in language modeling, common-sense reasoning, and time series forecasting.
February 12, 2025 | Presented by: Ali Behrouz | Watch TBD

TL;DR: Large language models typically process language at the token level, differing from the abstract reasoning of human cognition. This work presents the Large Concept Model (LCM), which operates on semantic "concepts" in the SONAR embedding space, moving beyond token-based manipulation. Trained for autoregressive sentence prediction, LCM demonstrates strong zero-shot generalization in generative tasks like summarization across multiple languages. Furthermore, the concept-based representation in SONAR facilitates multimodal extensions, enabling reasoning and generation grounded in diverse sensory inputs, ultimately fostering more human-like AI.
April 3, 2025 | Presented by: Maha Elbayad | Watch TBD

TL;DR: The paper introduces a novel method to generate coherent one-minute videos from text storyboards using Test-Time Training (TTT) layers, which are expressive RNN components whose hidden states are themselves neural networks. By inserting TTT layers into a pre-trained Diffusion Transformer, the model can handle long-range dependencies across video segments, enabling complex multi-scene storytelling.
April 17, 2025 | Presented by: Karan Dalal | Watch TBD